
Symflower Launches DevQualityEval: A New Benchmark for Enhancing Code Quality in Large Language Models
Symflower has recently introduced DevQualityEval, an innovative evaluation benchmark and framework designed to elevate the code quality generated by large language models (LLMs). This release will allow developers to assess and improve LLMs’ capabilities in real-world software development scenarios.
DevQualityEval offers a standardized benchmark and framework that allows developers to measure & compare the performance of various LLMs in generating high-quality code. This tool is useful for evaluating the effectiveness of LLMs in handling complex programming tasks and generating reliable test cases. By providing detailed metrics and comparisons, DevQualityEval aims to guide developers and users of LLMs in selecting suitable models for their needs.
The framework addresses the challenge of assessing code quality comprehensively, considering factors such as code compilation success, test coverage, and the efficiency of generated code. This multi-faceted approach ensures that the benchmark is robust and provides meaningful insights into the performance of different LLMs.
Key Features of DevQualityEval include the following:

Standardized Evaluation: DevQualityEval offers a consistent and repeatable way to evaluate LLMs, making it easier for developers to compare different models and track improvements over time.
Real-World Task Focus: The benchmark includes tasks representative of real-world programming challenges. This includes generating unit tests for various programming languages and ensuring that models are tested on practical and relevant scenarios.
Detailed Metrics: The framework provides in-depth metrics, such as code compilation rates, test coverage percentages, and qualitative assessments of code style and correctness. These metrics help developers understand the strengths and weaknesses of different LLMs.
Extensibility: DevQualityEval is designed to be extensible, allowing developers to add new tasks, languages, and evaluation criteria. This flexibility ensures the benchmark can evolve alongside AI and software development advancements.
Installation and Usage
Setting up DevQualityEval is straightforward. Developers must install Git and Go, clone the repository, and run the installation commands. The benchmark can then be executed using the ‘eval-dev-quality’ binary, which generates detailed logs and evaluation results.
## shell
git clone https://github.com/symflower/eval-dev-quality.git
cd eval-dev-quality
go install -v github.com/symflower/eval-dev-quality/cmd/eval-dev-quality
Developers can specify which models to evaluate and obtain comprehensive reports in formats such as CSV and Markdown. The framework currently supports openrouter.ai as the LLM provider, with plans to expand support to additional providers.
DevQualityEval evaluates models based on their ability to solve programming tasks accurately and efficiently. Points are awarded for various criteria, including the absence of response errors, the presence of executable code, and achieving 100% test coverage. For instance, generating a test suite that compiles and covers all code statements yields higher scores.
The framework also considers models’ efficiency regarding token usage and response relevance, penalizing models that produce verbose or irrelevant output. This focus on practical performance makes DevQualityEval a valuable tool for model developers and users seeking to deploy LLMs in production environments.
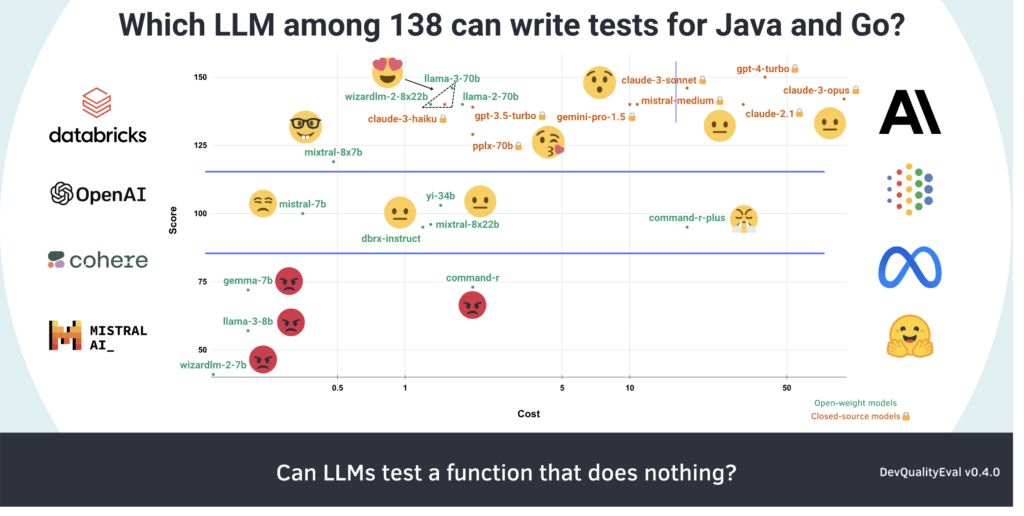
One of DevQualityEval’s key highlights is its ability to provide comparative insights into the performance of leading LLMs. For example, recent evaluations have shown that while GPT-4 Turbo offers superior capabilities, Llama-3 70B is significantly more cost-effective. These insights help users make informed decisions based on their requirements and budget constraints.
In conclusion, Symflower’s DevQualityEval is poised to become an essential tool for AI developers and software engineers. Providing a rigorous and extensible framework for evaluating code generation quality empowers the community to push the boundaries of what LLMs can achieve in software development.
Check out the GitHub page and Blog. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.









