
Salesforce AI Research Introduces BLIP-3-Video: A Multimodal Language Model for Videos Designed to Efficiently Capture Temporal Information Over Multiple Frames

Vision-language models (VLMs) are gaining prominence in artificial intelligence for their ability to integrate visual and textual data. These models play a crucial role in fields like video understanding, human-computer interaction, and multimedia applications, offering tools to answer questions, generate captions, and enhance decision-making based on video inputs. The demand for efficient video-processing systems is growing as video-based tasks proliferate across industries, from autonomous systems to entertainment and medical applications. Despite advances, handling the vast amount of visual information in videos remains a core challenge in developing scalable and efficient VLMs.
A critical issue in video understanding is that existing models often rely on processing each video frame individually, generating thousands of visual tokens. This process consumes extensive computational resources and time, limiting the model’s ability to efficiently handle long or complex videos. The challenge is reducing the computational load while capturing relevant visual and temporal details. Without a solution, tasks requiring real-time or large-scale video processing become impractical, creating a need for innovative approaches that balance efficiency and accuracy.
Current solutions attempt to reduce the number of visual tokens through techniques such as pooling across frames. Models like Video-ChatGPT and Video-LLaVA focus on spatial and temporal pooling mechanisms to condense frame-level information into smaller tokens. However, these methods still generate many tokens, with models like MiniGPT4-Video and LLaVA-OneVision producing thousands of tokens, leading to inefficient handling of longer videos. These models often need help to optimize token efficiency and video processing performance, necessitating more effective solutions to streamline token management.
In response, researchers from Salesforce AI Research introduced BLIP-3-Video, an advanced VLM specifically designed to address the inefficiencies in video processing. The model incorporates a “temporal encoder” that dramatically reduces the visual tokens required to represent a video. By limiting the token count to as few as 16 to 32 tokens, the model significantly improves computational efficiency without sacrificing performance. This breakthrough allows BLIP-3-Video to perform video-based tasks with much lower computational costs, making it a groundbreaking step toward scalable video understanding solutions.


The temporal encoder in BLIP-3-Video is central to its ability to process videos more efficiently. It employs a learnable spatio-temporal attentional pooling mechanism that extracts only the most informative tokens across video frames. The system consolidates spatial and temporal data from each frame, transforming them into a compact set of video-level tokens. The model includes a vision encoder, a frame-level tokenizer, and an autoregressive language model that generates text or answers based on video input. The temporal encoder uses sequential models and attention mechanisms to retain the video’s core information while reducing redundant data, ensuring that BLIP-3-Video can handle complex video tasks efficiently.
Performance results demonstrate BLIP-3-Video’s superior efficiency compared to larger models. The model achieves video question-answering (QA) accuracy similar to state-of-the-art models, such as Tarsier-34B, while using a mere fraction of the visual tokens. For instance, Tarsier-34B uses 4608 tokens for 8 video frames, while BLIP-3-Video reduces this number to just 32 tokens. Despite this reduction, BLIP-3-Video still maintains strong performance, achieving a score of 77.7% on the MSVD-QA benchmark and 60.0% on the MSRVTT-QA benchmark, both of which are widely used datasets for evaluating video-based question-answering tasks. These results underscore the model’s ability to retain high levels of accuracy while operating with fewer resources.
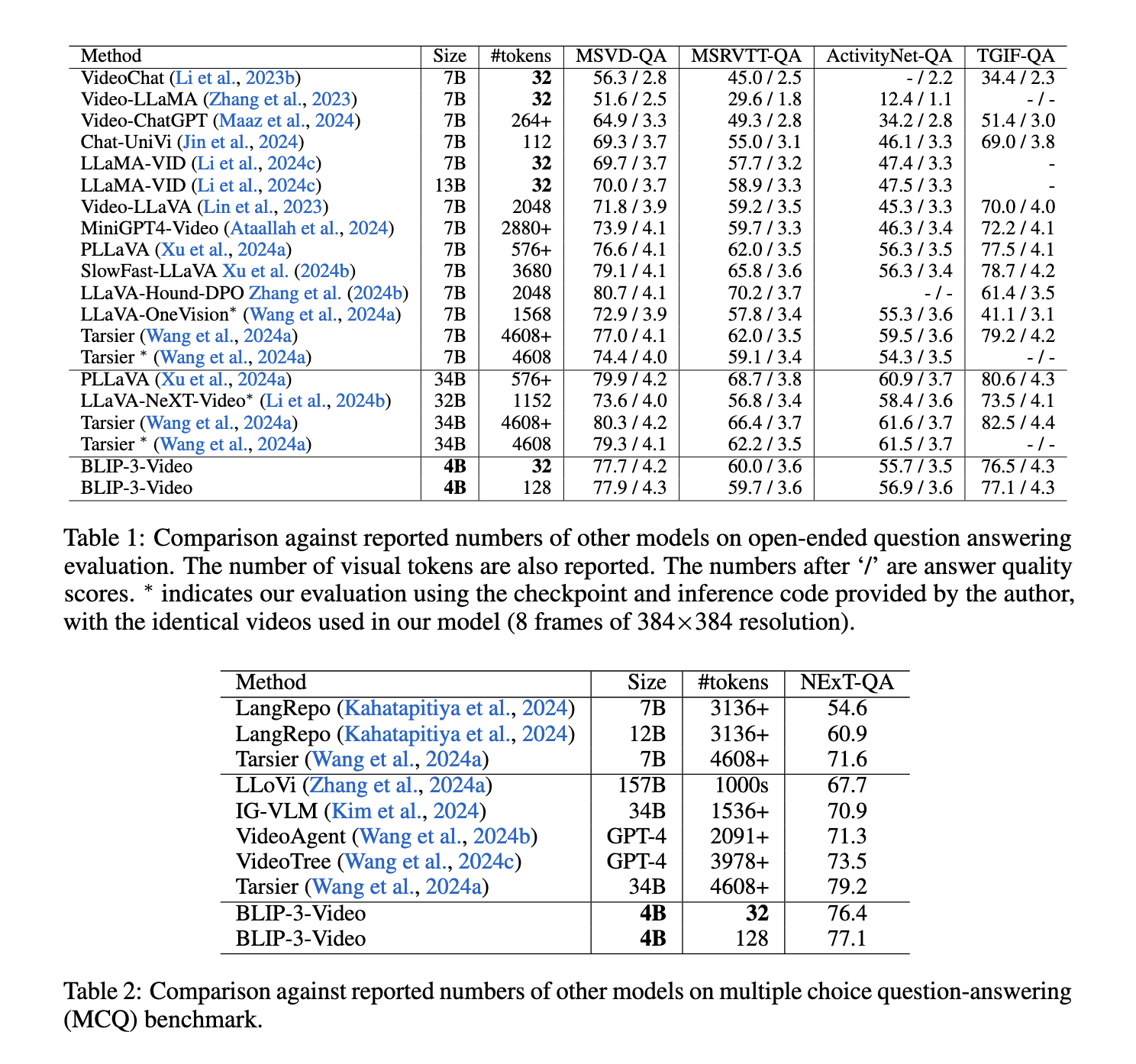
The model performed exceptionally well on multiple-choice question-answering tasks, such as the NExT-QA dataset, scoring 77.1%. This is particularly noteworthy given that it used only 32 tokens per video, significantly fewer than many competing models. Additionally, on the TGIF-QA dataset, which requires understanding dynamic actions and transitions in videos, the model achieved an impressive 77.1% accuracy, further highlighting its efficiency in handling complex video queries. These results establish BLIP-3-Video as one of the most token-efficient models available, providing comparable or superior accuracy to much larger models while dramatically reducing computational overhead.

In conclusion, BLIP-3-Video addresses the challenge of token inefficiency in video processing by introducing an innovative temporal encoder that reduces the number of visual tokens while maintaining high performance. Developed by Salesforce AI Research, the model demonstrates that processing complex video data with far fewer tokens than previously thought necessary is possible, offering a more scalable and efficient solution for video understanding tasks. This advancement represents a significant step forward in vision-language models, paving the way for more practical applications of AI in video-based systems across various industries.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.









