Researchers from Intel and Salesforce Propose SynthKG: A Multi-Step Document-Level Ontology-Free Knowledge Graphs Synthesis Workflow based on LLMs
Knowledge Graph (KG) synthesis is gaining traction in artificial intelligence research because it can construct structured knowledge representations from expansive, unstructured text data. These structured graphs have pivotal applications in areas requiring information retrieval and reasoning, such as question answering, complex data summarization, and retrieval-augmented generation (RAG). KGs effectively link and organize information, enabling models to process and answer intricate queries more accurately. Despite these advantages, creating high-quality KGs from large datasets remains challenging due to the need for both coverage and efficiency, which become increasingly difficult to maintain with traditional methods when handling massive amounts of data.
One of the central problems in KG synthesis is reducing the inefficiency in generating comprehensive graphs, especially for large-scale corpora that require complex knowledge representations. Existing KG extraction techniques typically employ large language models (LLMs) capable of advanced processing but can also be computationally prohibitive. These methods generally use zero-shot or few-shot prompt-based approaches to structure KGs, often involving extensive API calls and high costs. These approaches need to be revised in handling lengthy documents comprehensively, leading to issues such as incomplete data representation and significant information loss. This creates a gap between the growing demand for effective data synthesis methods and the available KG construction tools, which need more specialization for ontology-free KG evaluation and benchmarking.
In current practice, traditional methods of KG construction rely heavily on LLM prompting to derive knowledge triplets. This single-step, in-context learning approach presents several limitations. For example, the computational demand increases as the corpus grows, and each additional API call to process data increases costs. Also, there needs to be a standardized dataset or evaluation metric for assessing document-level, ontology-free KGs, creating further challenges for researchers aiming to benchmark the effectiveness of their models. With large-scale applications in mind, there is a compelling need for models that can manage detailed document processing efficiently without compromising data quality.
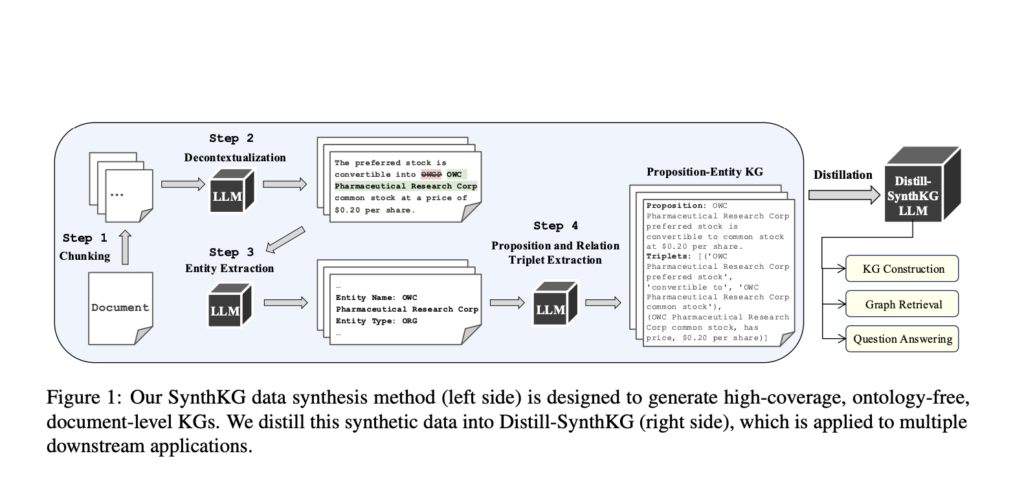
The Salesforce and Intel Labs researchers introduced SynthKG, a multi-step KG construction workflow that enhances coverage and efficiency. SynthKG breaks down document processing into manageable stages, ensuring that information remains intact by chunking documents and then processing each segment to identify entities, relations, and relevant propositions. A distilled model, Distill-SynthKG, was further developed by fine-tuning a smaller LLM using KGs generated from SynthKG. This distillation reduces the multi-step workflow into a single-step process, significantly reducing computational requirements. With Distill-SynthKG, the need for repeated LLM prompts is minimized, enabling high-quality KG generation with a fraction of the resources required by conventional approaches.

The SynthKG workflow involves document segmentation, which splits each input document into independent, semantically complete chunks. During this chunking process, entity disambiguation is applied to maintain a consistent reference for each entity across segments. For example, if an individual is introduced by full name in one chunk, all future mentions are updated to ensure contextual accuracy. This approach improves the coherence of each segment while preventing the loss of important relationships between entities. The next stage involves relation extraction, where entities and their types are identified and linked based on predefined propositions. Each KG segment is further enriched with a quadruplet format, providing an intermediate, indexable unit for better retrieval accuracy. By structuring each chunk independently, SynthKG avoids redundancy and maintains high-quality data integrity throughout the KG construction process.
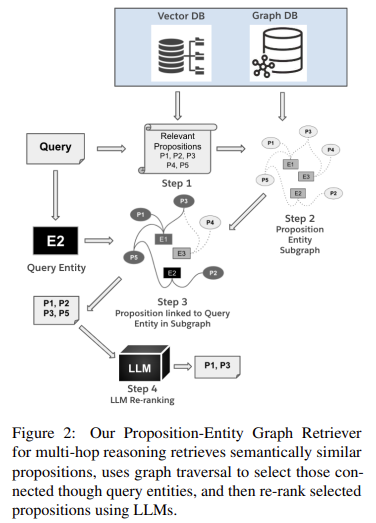
Distill-SynthKG has shown substantial improvements over baseline models in experimental settings. For instance, the model generated over 46.9% coverage on MuSiQue and 58.2% on 2WikiMultiHopQA in terms of triplet coverage, outperforming larger models by a margin of up to 6.26% in absolute terms across various test datasets. Regarding retrieval and question-answering tasks, Distill-SynthKG consistently surpassed the performance of even models eight times larger by reducing computational costs while enhancing retrieval accuracy. This efficiency is evident in the Graph+LLM retriever, where the KG model demonstrated a 15.2% absolute improvement in retrieval tasks, particularly when answering multi-hop reasoning questions. These results confirm the efficacy of a structured multi-step approach in maximizing KG coverage and enhancing accuracy without relying on oversized LLMs.
The experimental results highlight the success of Distill-SynthKG in delivering high-performance KG synthesis with lower computational demand. By training smaller models on high-quality document-KG pairs from SynthKG, researchers achieved improved semantic accuracy, resulting in triplet densities consistent across documents of various lengths. Also, the SynthKG model produced KGs with greater triplet density, remaining steady across documents up to 1200 words, demonstrating the workflow’s scalability. Evaluated across benchmarks such as MuSiQue and HotpotQA, the model’s improvements were validated using new KG coverage metrics, which included proxy triplet coverage and semantic matching scores. These metrics further confirmed the model’s suitability for large-scale, ontology-free KG tasks, as it successfully synthesized detailed KGs that supported high-quality retrieval and multi-hop question-answering tasks.
Key Takeaways from the research:
Efficiency: Distill-SynthKG reduces the need for repeated LLM calls by consolidating KG construction into a single-step model, cutting computational costs.
Improved Coverage: Achieved 46.9% triplet coverage on MuSiQue and 58.2% on 2WikiMultiHopQA, outperforming larger models by 6.26% on average across datasets.
Enhanced Retrieval Accuracy: A 15.2% improvement in multi-hop question-answering retrieval accuracy with Graph+LLM retrieval.
Scalability: Maintained consistent triplet density across documents of varying lengths, demonstrating suitability for large datasets.
Broader Applications: The model supports efficient KG generation for various domains, from healthcare to finance, by accurately accommodating ontology-free KGs.

In conclusion, the research findings emphasize the impact of an optimized KG synthesis process that prioritizes coverage, accuracy, and computational efficiency. Distill-SynthKG not only sets a new benchmark for KG generation but also presents a scalable solution that accommodates various domains, paving the way for more efficient retrieval and question-answering frameworks. This approach could have broad implications for advancing AI’s ability to generate and structure large-scale knowledge representations, ultimately enhancing the quality of knowledge-based applications across sectors.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.