Understanding Memorization in Diffusion Models: A Statistical Physics Approach to Manifold-Supported Data
Generative diffusion models have revolutionized image and video generation, becoming the foundation of state-of-the-art generation software. While these models excel at handling complex high-dimensional data distributions, they face a critical challenge: the risk of complete training set memorization in low-data scenarios. This memorization capability raises legal concerns like copyright laws, as these models might reproduce exact copies of training data rather than generate novel content. The challenge lies in understanding when these models truly generalize vs when they simply memorize, especially considering that natural images typically have their variability confined to a small subspace of possible pixel values.
Recent research efforts have explored various aspects of diffusion models’ behavior and capabilities. The Local Intrinsic Dimensionality (LID) estimation methods have been developed to understand how these models learn data manifold structures, focusing on analyzing the dimensional characteristics of individual data points. Some approaches examine how generalization emerges based on dataset size and manifold dimension variations along diffusion trajectories. Moreover, Statistical physics approaches are used to analyze the backward process of diffusion models as phase transitions and spectral gap analysis has been used to study generative processes. However, these methods either focus on exact scores or fail to explain the interplay between memorization and generalization in diffusion models.
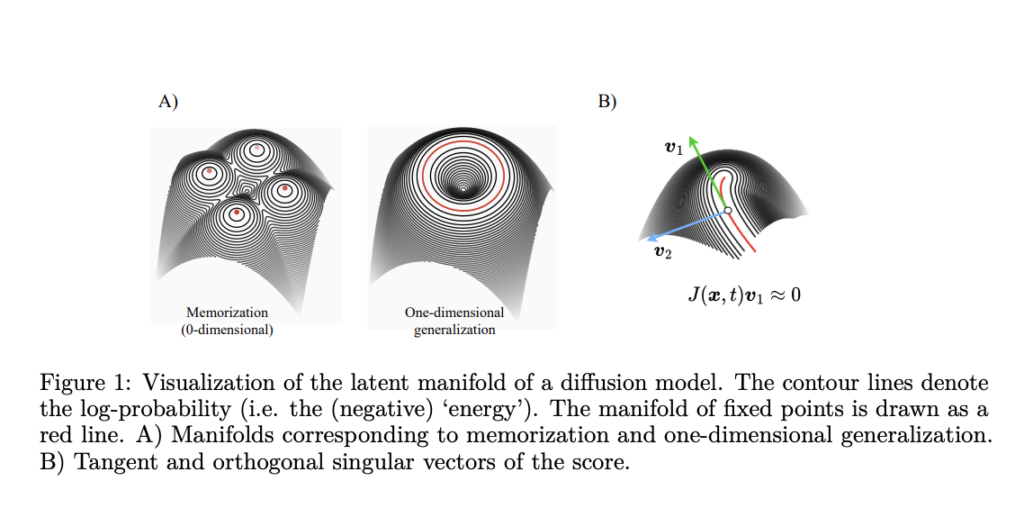
Researchers from Bocconi University, OnePlanet Research Center Donders Institute, RPI, JADS Tilburg University, IBM Research, and Radboud University Donders Institute have extended the theory of memorization in generative diffusion to manifold-supported data using statistical physics techniques. Their research reveals an unexpected phenomenon where higher variance subspaces are more prone to memorization effects under certain conditions, which leads to selective dimensionality reduction where key data features are retained without fully collapsing to individual training points. The theory presents a new understanding of how different tangent subspaces are affected by memorization at varying critical times and dataset sizes, with the effect depending on local data variance along specific directions.
The experimental validation of the proposed theory focuses on diffusion networks trained on linear manifold data structured with two distinct subspaces: one with high variance (1.0) and another with low variance (0.3). The network’s spectral analysis reveals behavior patterns that align with theoretical predictions for different dataset sizes and time parameters. The network maintains a manifold gap that holds steady even at small time values for large datasets, suggesting a natural tendency toward generalization. The spectra show selective preservation of the low-variance gap while losing the high-variance subspace, matching theoretical predictions at intermediate dataset sizes.

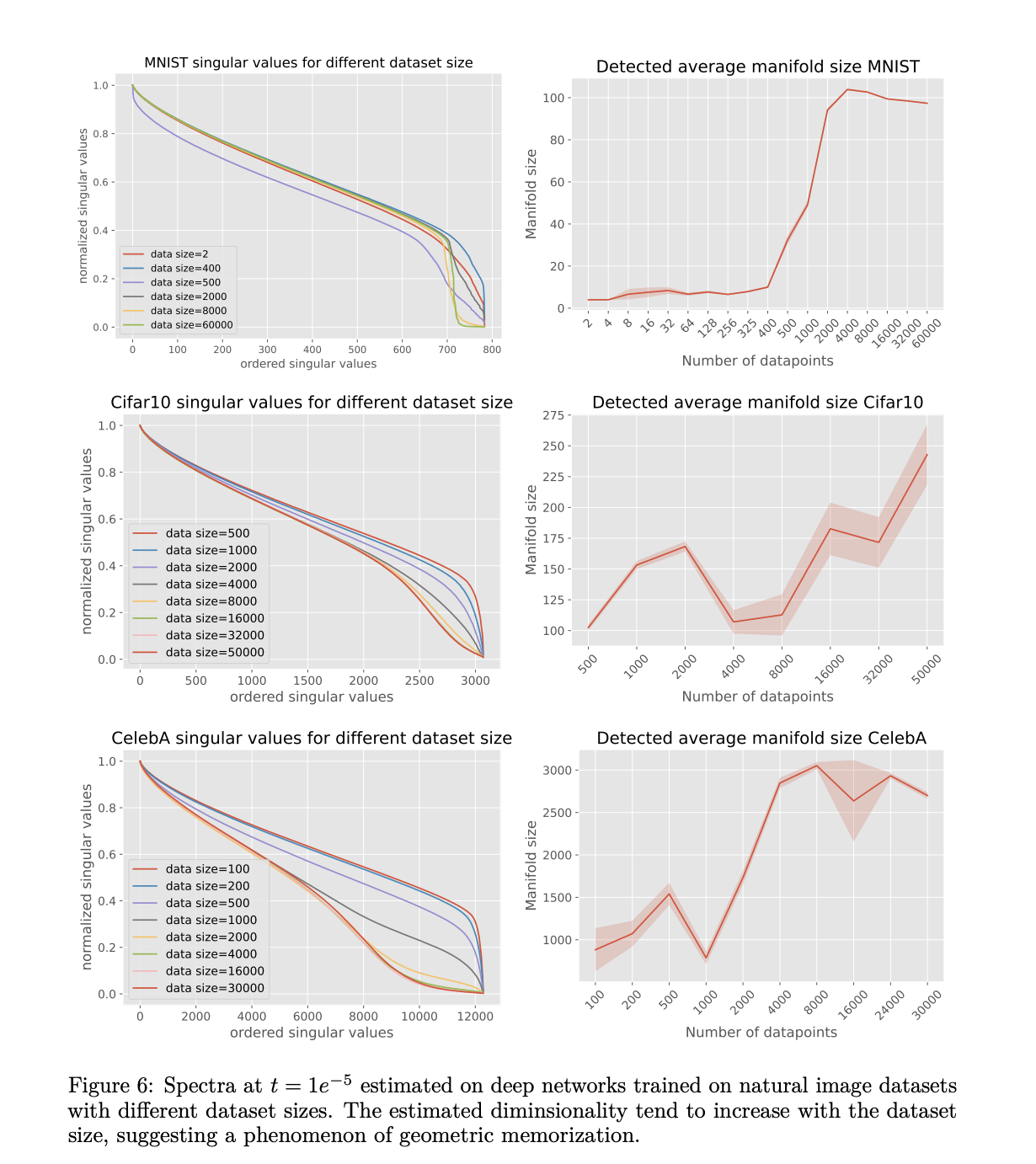
Experimental analysis across MNIST, Cifar10, and Celeb10 datasets reveal distinct patterns in how latent dimensionality varies with dataset size and diffusion time. MNIST networks demonstrate clear spectral gaps, with dimensionality increasing from 400 data points to a high value of around 4000 points. While Cifar10 and Celeb10 show less distinct spectral gaps, they show predictable changes in spectral inflection points as dataset size varies. Moreover, a notable finding is Cifar10’s unsaturated dimensionality growth, suggesting ongoing geometric memorization effects even with the full dataset. These results validate the theoretical predictions about the relationship between dataset size and geometric memorization across different image data types.
In conclusion, researchers presented a theoretical framework for understanding generative diffusion models through the lens of statistical physics, differential geometry, and random matrix theory. The paper contains crucial insights into how these models balance memorization and generalization, especially in dataset size and data variance patterns. While the current analysis focuses on empirical score functions, the theoretical framework lays the groundwork for future investigations into Jacobian spectra of trained models and their deviations from empirical predictions. These findings are valuable for advancing the understanding of generalization abilities for diffusion models, which is essential for their continued development.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.