QoQ and QServe: A New Frontier in Model Quantization Transforming Large Language Model Deployment
Quantization, a method integral to computational linguistics, is essential for managing the vast computational demands of deploying large language models (LLMs). It simplifies data, thereby facilitating quicker computations and more efficient model performance. However, deploying LLMs is inherently complex due to their colossal size and the computational intensity required. Effective deployment strategies must balance performance, accuracy, and computational overhead.
In LLMs, traditional quantization techniques convert high-precision floating-point numbers into lower-precision integers. While this process reduces memory usage and accelerates computation, it often incurs significant computational overhead. This overhead can degrade model accuracy, as the precision reduction can lead to substantial losses in data fidelity.
Researchers from MIT, NVIDIA, UMass Amherst, and MIT-IBM Watson AI Lab introduced the Quattuor-Octo-Quattuor (QoQ) algorithm, a novel approach that refines quantization. This innovative method employs progressive group quantization, which mitigates the accuracy losses typically associated with standard quantization methods. By quantizing weights to an intermediate precision and refining them to the target precision, the QoQ algorithm ensures that all computations are adapted to the capabilities of current-generation GPUs.
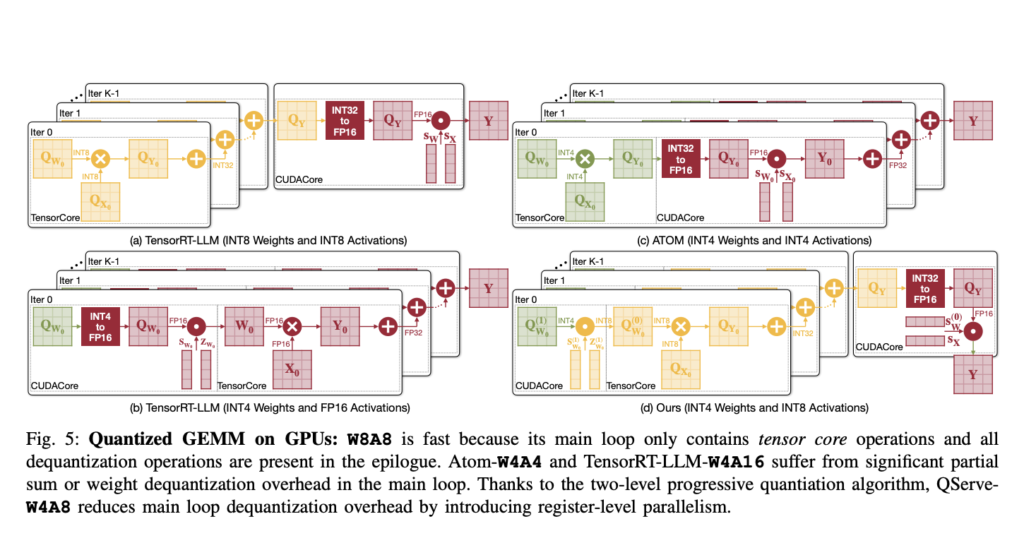
The QoQ algorithm utilizes a two-stage quantization process. Initially, weights are quantized to 8 bits using per-channel FP16 scales; these intermediates are further quantized to 4 bits. This approach enables General Matrix Multiplication (GEMM) operations on INT8 tensor cores, enhancing computational throughput and reducing latency. The algorithm also incorporates SmoothAttention, a technique that adjusts the quantization of activation keys to optimize performance further.

The QServe system was developed to support the deployment of the QoQ algorithm. QServe provides a tailored runtime environment that maximizes the efficiency of LLMs by exploiting the algorithm’s full potential. It integrates seamlessly with current GPU architectures, facilitating operations on low-throughput CUDA cores and significantly boosting processing speed. This system design reduces the quantization overhead by focusing on compute-aware weight reordering and fused attention mechanisms, essential for maintaining throughput and minimizing latency in real-time applications.
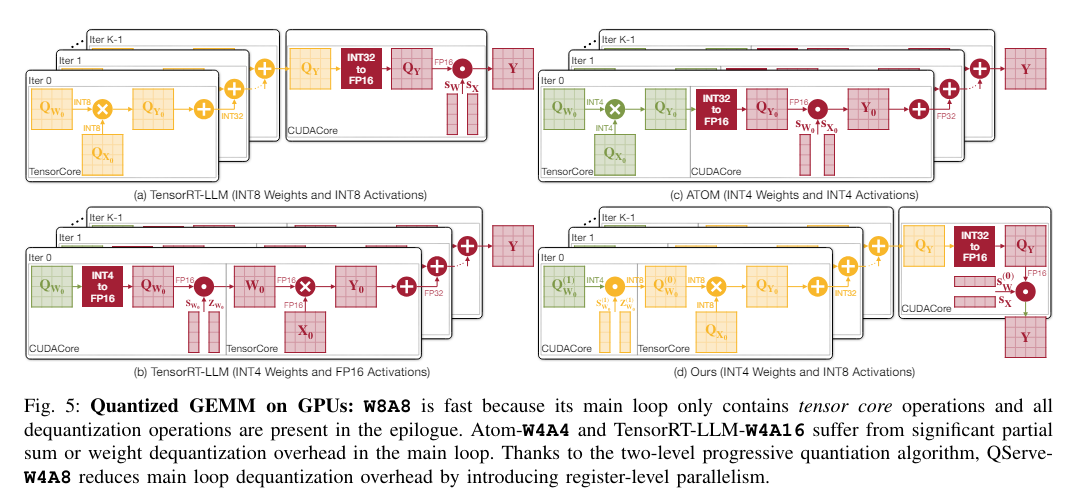
Performance evaluations of the QoQ algorithm indicate substantial improvements over previous methods. In testing, QoQ improved the maximum achievable serving throughput of Llama-3-8B models by up to 1.2 times on NVIDIA A100 GPUs and up to 1.4 times on L40S GPUs. Remarkably, on the L40S platform, QServe, a system designed to support QoQ, achieved throughput enhancements of up to 3.5 times compared to the same model on A100 GPUs, significantly reducing the cost of LLM serving.

In conclusion, the study introduces the QoQ algorithm and QServe system as groundbreaking solutions to the challenges of deploying LLMs efficiently. By addressing the significant computational overhead and accuracy loss inherent in traditional quantization methods, QoQ and QServe markedly enhance LLM serving throughput. The results from the implementation demonstrate up to 2.4 times faster processing on advanced GPUs, substantially reducing both the computational demands and the economic costs associated with LLM deployment. This advancement paves the way for broader adoption and more effective use of large language models in real-world applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.