LLM-KT: A Flexible Framework for Enhancing Collaborative Filtering Models with Embedded LLM-Generated Features
Collaborative Filtering (CF) is widely used in recommender systems to match user preferences with items but often struggles with complex relationships and adapting to evolving user interactions. Recently, researchers have explored using LLMs to enhance recommendations by leveraging their reasoning abilities. LLMs have been integrated into various stages, from knowledge generation to candidate ranking. While effective, this integration can be costly, and existing methods, such as KAR and LLM-CF, only enhance context-aware CF models by adding LLM-derived textual features.
Researchers from HSE University, MIPT, Ural Federal University, Sber AI Lab, AIRI, and ISP RAS developed LLM-KT, a flexible framework designed to enhance CF models by embedding LLM-generated features into intermediate model layers. Unlike previous methods that rely on directly inputting LLM-derived features, LLM-KT integrates these features within the model, allowing it to reconstruct and utilize the embeddings internally. This adaptable approach requires no architectural changes, making it suitable for various CF models. Experiments on the MovieLens and Amazon datasets show that LLM-KT significantly improves baseline models, achieving a 21% increase in NDCG@10 and performing comparably with state-of-the-art context-aware methods.
The proposed method introduces a knowledge transfer approach that enhances CF models by embedding LLM-generated features within a designated internal layer. This approach allows CF models to intuitively learn user preferences without altering their architecture, creating profiles based on user-item interactions. LLMs use prompts tailored to each user’s interaction data to generate preference summaries, or “profiles,” which are then converted into embeddings with a pre-trained text model, such as “text-embedding-ada-002.” To optimize this integration, the CF model is trained with an auxiliary pretext task, combining the original model loss with a reconstruction loss that aligns profile embeddings with the CF model’s internal representations. This setup uses UMAP for dimensional alignment and RMSE for the reconstruction loss, ensuring that the model accurately represents user preferences.
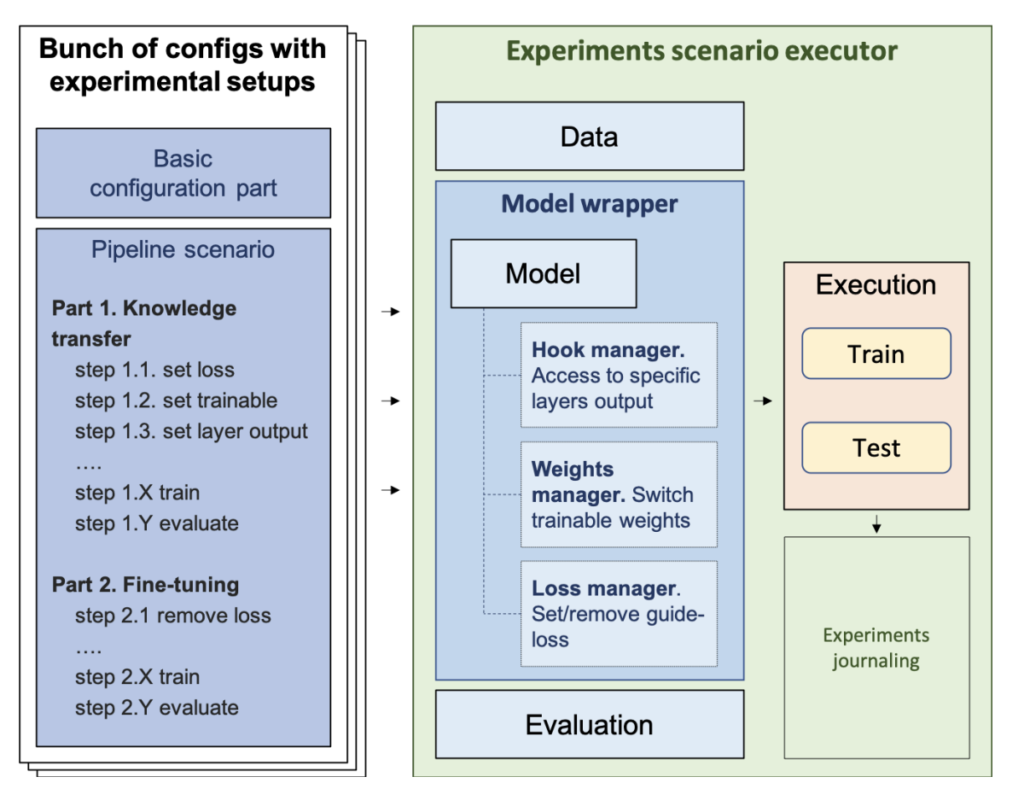
The LLM-KT framework, built on RecBole, supports flexible experimental configurations, allowing researchers to define detailed pipelines through a single configuration file. Key features include support for integrating LLM-generated profiles from various sources, an adaptable configuration system, and batch experiment execution with analytical tools for comparing results. The framework’s internal structure includes a Model Wrapper, which oversees essential components like the Hook Manager for accessing intermediate representations, the Weights Manager for fine-tuning control, and the Loss Manager for custom loss adjustments. This modular design streamlines knowledge transfer and fine-tuning, enabling researchers to efficiently test and refine CF models.

The experimental setup evaluates the proposed knowledge transfer method for CF models in two ways: for traditional models using only user-item interaction data and for context-aware models that can utilize input features. Experiments were conducted on Amazon’s “CD and Vinyl” and MovieLens datasets, using a 70-10-20% train-validation-test split. Baseline CF models included NeuMF, SimpleX, and MultVAE, while KAR, DCN, and DeepFM were used for context-aware comparisons. The method was assessed with ranking metrics (NDCG@K, Hits@K, Recall@K) and AUC-ROC for click-through-rate tasks. Results showed consistent performance improvements across models, with comparable versatility and accuracy to existing approaches like KAR.
The LLM-KT framework offers a versatile way to enhance CF models by embedding LLM-generated features within an intermediate layer, allowing models to leverage these embeddings internally. Unlike traditional methods that input LLM features directly, LLM-KT enables seamless knowledge transfer across various CF architectures without altering their structure. Built on the RecBole platform, the framework allows flexible configurations for easy integration and adaptation. Experiments on MovieLens and Amazon datasets confirm significant performance gains, showing that LLM-KT is competitive with advanced methods in context-aware models and applicable across a wider range of CF models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.