
Microsoft Open-Sources bitnet.cpp: A Super-Efficient 1-bit LLM Inference Framework that Runs Directly on CPUs
The rapid growth of large language models (LLMs) has brought impressive capabilities, but it has also highlighted significant challenges related to resource consumption and scalability. LLMs often require extensive GPU infrastructure and enormous amounts of power, making them costly to deploy and maintain. This has particularly limited their accessibility for smaller enterprises or individual users without access to advanced hardware. Moreover, the energy demands of these models contribute to increased carbon footprints, raising sustainability concerns. The need for an efficient, CPU-friendly solution that addresses these issues has become more pressing than ever.
Microsoft recently open-sourced bitnet.cpp, a super-efficient 1-bit LLM inference framework that runs directly on CPUs, meaning that even large 100-billion parameter models can be executed on local devices without the need for a GPU. With bitnet.cpp, users can achieve impressive speedups of up to 6.17x while also reducing energy consumption by 82.2%. By lowering the hardware requirements, this framework could potentially democratize LLMs, making them more accessible for local use cases and enabling individuals or smaller businesses to harness AI technology without the hefty costs associated with specialized hardware.

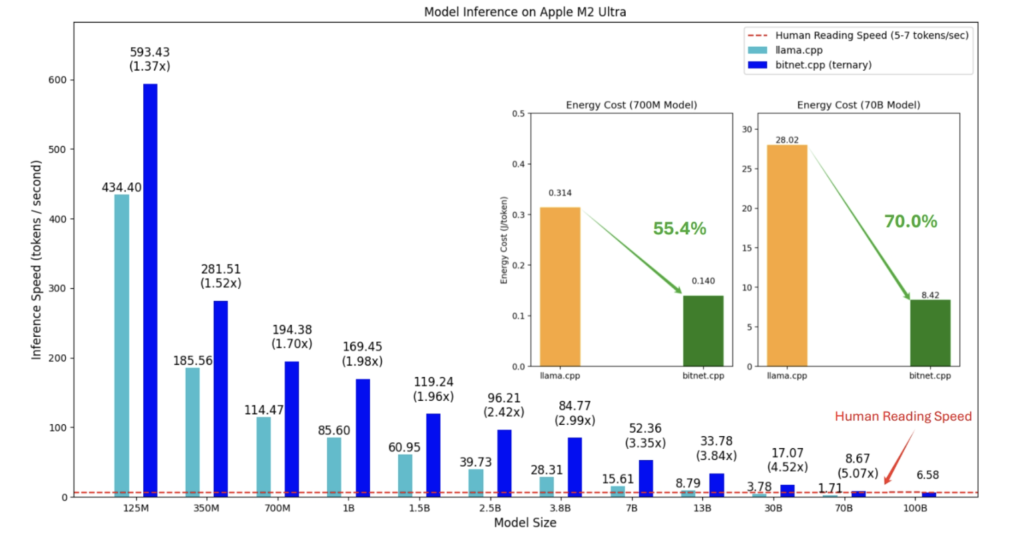
Technically, bitnet.cpp is a powerful inference framework designed to support efficient computation for 1-bit LLMs, including the BitNet b1.58 model. The framework includes a set of optimized kernels tailored to maximize the performance of these models during inference on CPUs. Current support includes ARM and x86 CPUs, with additional support for NPUs, GPUs, and mobile devices planned for future updates. Benchmarks reveal that bitnet.cpp achieves speedups of between 1.37x and 5.07x on ARM CPUs, and between 2.37x and 6.17x on x86 CPUs, depending on the size of the model. Additionally, energy consumption sees reductions ranging from 55.4% to 82.2%, making the inference process much more power efficient. The ability to achieve such performance and energy efficiency allows users to run sophisticated models at speeds comparable to human reading rates (about 5-7 tokens per second), even on a single CPU, offering a significant leap for running LLMs locally.
The importance of bitnet.cpp lies in its potential to redefine the computation paradigm for LLMs. This framework not only reduces hardware dependencies but also sets a foundation for the development of specialized software stacks and hardware that are optimized for 1-bit LLMs. By demonstrating how effective inference can be achieved with low resource requirements, bitnet.cpp paves the way for a new generation of local LLMs (LLLMs), enabling more widespread, cost-effective, and sustainable adoption. These benefits are particularly impactful for users interested in privacy, as the ability to run LLMs locally minimizes the need to send data to external servers. Additionally, Microsoft’s ongoing research and the launch of its “1-bit AI Infra” initiative aim to further industrial adoption of these models, highlighting bitnet.cpp’s role as a pivotal step toward the future of LLM efficiency.

In conclusion, bitnet.cpp represents a major leap forward in making LLM technology more accessible, efficient, and environmentally friendly. With significant speedups and reductions in energy consumption, bitnet.cpp makes it feasible to run even large models on standard CPU hardware, breaking the reliance on expensive and power-hungry GPUs. This innovation could democratize access to LLMs and promote their adoption for local use, ultimately unlocking new possibilities for individuals and industries alike. As Microsoft continues to push forward with its 1-bit LLM research and infrastructure initiatives, the potential for more scalable and sustainable AI solutions becomes increasingly promising.
Check out the GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.









